关于页面莫名其妙出现空白的编码错误
- 2016-06-05 17:20:30
- 幻音い
- 7540
温馨提示: 这篇文章于3677天前编写,现在可能不再适用或落后.
在很久之前就发现了这个问题,一般正常的页面是GBK或UTF8的编码格式,但是有些时候会变成一种叫UTF8+BOM的编码,一般是不怎么注意的。然而在调试的时候,咦?这怎么多了一块,然后查看源代码,噢?这源代码怎么和写的代码不一样啊?head里面居然是空的?head里面的内容怎么全部跑到body里面去了?

通常这些问题本应该是不会出现的,但是有时候为了方便会用记事本去修改代码,没错就是windows自带的记事本,修改完成,保存。恩,没什么问题,打开页面一看!代码结构有问题!查看css半天都没找到问题,最后才发现编码怎么不对劲....
一般这种情况都是在服务器上windows使用记事本修改的才会出现问题。
恩,前端问题不大,只是显示问题。然后这几天做接口什么的,然后最后需要返回json数据。然后提供给用户转为数组。好了。
使用php在最后的时候 json_decode() 咦?他喵的怎么不行?报错!什么鬼,然后复制粘贴到某json解析站上面去看,我凑,还是报错?然后自己照着样子写了出来。嘿?怎么这次就能转了..
带BOM的编码
{
"a": "1"
}
```正常的UTF8编码
{ "a": "1" }
```
复制上面的json数据,去任意json解析器,你会发现带bom的直接报错,正常的则不会。
JSON.parse: unexpected character at line 1 column 1 of the JSON data
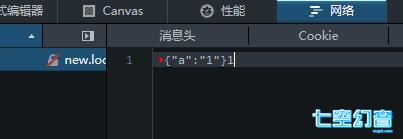
而且,在审查元素查看网络响应的时候,你会发现在火狐下会多出一个红色小圆点。并且还会多出一些无关的数据。
所以说,我在服务器上有时候懒得时候直接使用记事本修改,然后就一堆问题。尽量使用代码编辑器,多注意编码集QAQ。
随便看看

阁下需要登录后才可以查看评论哦~